

El Modelo de objetos de documento es una parte fundamental de la World Wide Web. Para abreviar, DOM es un conjunto de estándares API que definen cómo un navegador debe construir un documento web y cómo los desarrolladores pueden manipular objetos.
Veremos un poco más de cerca cómo funciona realmente el DOM. El modelo ha existido durante años y actualmente reside en DOM nivel 3 (documentación DOM3 aquí). Hay un DOM4 actualmente en el borrador del editor con algunas nuevas especificaciones próximamente. Por ahora podemos enfocarnos en una breve comprensión de cómo surgió el modelo de objetos.
Una lección de historia
Durante los primeros días de las secuencias de comandos web, no había una forma estándar de acceder a los objetos de la página. Esto permitió que los principales navegadores entraran y escribieran sus propios estándares y reglas para la manipulación de documentos. Las compañías de software incluso escribieron sus propios lenguajes de scripting, como VBScript de Microsoft y Applescript de Apple.
Los primeros modelos fueron muy limitados. Solo se puede acceder a elementos específicos como imágenes o entradas de formulario. Con el tiempo, el World Wide Web Consortium desarrolló un modelo estándar que siguió a la mayoría de los editores de software. En particular, Internet Explorer, Netscape, Safari y Opera de Microsoft.
Actualmente, el DOM ha pasado por muchas revisiones y permite una manipulación muy precisa de los elementos de la página. Con librerías de script como jQuery y MooTools Los desarrolladores pueden pasar mucho menos tiempo colgando de errores.
Modern DOM Scripting Today
JavaScript es, con mucho, el lenguaje más popular entre los desarrolladores. Originalmente comenzó como un proyecto de código abierto por Netscape en 1995. Se basa en el popular lenguaje de programación Java y ha sido modificado por innumerables comunidades de desarrolladores web.
El DOM en sí solo es útil en situaciones en las que se puede acceder a los objetos. La mayoría de los navegadores compatibles con los estándares de hoy en día son compatibles con todos los elementos y métodos para la manipulación de DOM en su totalidad Con esta estandarización del modelo de objetos, hemos visto un aumento en las funciones de scripts y páginas simples.
El árbol de documentos
Al visualizar el DOM se puede entender fácilmente en comparación con un árbol. Cuando un documento se carga, cada elemento de la página se guarda en la memoria como un nuevo objeto. Estos a veces se conocen como nodos del arbol.
Como ejemplo, cada página HTML adecuada debe comenzar con un elemento HTML y todo el contenido de la página debe cargarse dentro de un cuerpo elemento. Esto significa que la jerarquía de su árbol comienza en un elemento HTML raíz y atraviesa su primer nodo cuerpo.
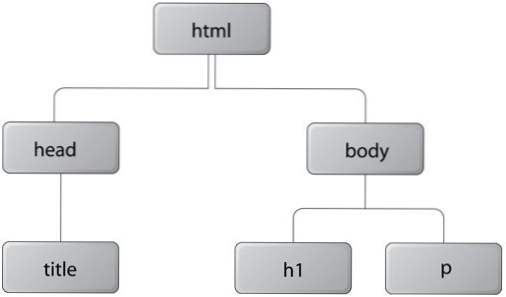
Esta es una idea simple pero proporciona un poder inmenso a los desarrolladores. A partir de esto, podemos extraer muchos tipos de elementos de la página simplemente accediendo a su nodo o ubicación específica en el documento. Se podría escribir una pequeña secuencia de comandos para extraer todas las imágenes de una página y empujarlas en una matriz para su almacenamiento.
Desde aquí es posible acceder a cada elemento de imagen a través de JavaScript. A continuación he añadido un código que establece 2 variables. El primero guarda el objeto de la tercera imagen en la memoria, mientras que el segundo tira del src cadena del elemento.
Métodos de nodo
Una vez que tenga la capacidad de manipular y acceder a los nodos, podrá aplicarles funciones. El modelo de objetos no es solo para atravesar la página, sino también para aplicar nuevos efectos.
Estos se llaman metodos y están escritos en la especificación DOM. Al imaginar un sistema de árbol basado en nodos, estos métodos eliminarán casi cualquier confusión. A continuación se muestra una pequeña lista de ejemplos de algunos métodos populares que puede usar en los nodos:
nodeA.firstChildnodeA.lastChildnodeA.parentNodenodeA.nextSiblingnodeA.prevSibling
La mayoría de estos métodos se pueden utilizar dentro de una declaración de variable o declaración de retorno de función. Devolverán un objeto desde el DOM en relación con su ubicación actual.
Los dos primeros tomarán el primer nodo interno y el último nodo interno, respectivamente. Esto es lo que la palabra clave. niño se supone que representa, con nodoA siendo el padre de ambos hijos. Esto también debería explicar cómo parentNode funciona como puede extraer el objeto de nodo que se encuentra directamente sobre su selector actual.

Ambas funciones de hermanos son desconocidas para la mayoría y elementos de destino en el mismo nivel jerárquico. Como ejemplo, si estuviera recorriendo una lista desordenada con 3 li Etiquetas que solo puedes llamar proximo hermano 2 veces antes de regresar nulo. Muchas de estas funciones se han reducido desde entonces a bibliotecas de terceros en métodos más rápidos y precisos.
Clases de elementos y IDs
Una de las formas más populares de recuperar información de objetos es a través de la orientación directa. Si ha escrito un código HTML, debe conocer los atributos de clase e ID. Estos pueden establecerse en cualquier elemento de la página y son notoriamente útiles para aplicar estilos CSS.

Cuando crea estos atributos, el DOM los reconoce como entornos separados del documento general. Las identificaciones deben ser únicas en su página y causarán errores en las secuencias de comandos si duplica el mismo nombre. Las clases pueden contener innumerables elementos, aunque se pueden atascar rápidamente.
El metodo popular getElementById () ha sido utilizado por los desarrolladores durante una década para simplificar el proceso de manipulación de objetos. Este método toma un solo argumento de cadena que contiene el valor de ID de cualquier elemento que esté buscando segmentar. Como tal puedes cambiar una imagen src atribuye rápidamente con un código similar:
Avances en el modelo
Con el lanzamiento de la popular biblioteca jQuery es más fácil que nunca desarrollar scripts potentes. Funciones más antiguas como getElementById () y getElementsByTagName () siguen siendo accesibles, aunque en desuso por la mayoría de los estándares.
La forma más rápida de comenzar a manipular el DOM es accediendo a objetos a través de jQuery. Un método simple llamado $ (documento) .ready ({}) es todo lo que se requiere para ejecutar un nuevo evento. los $() la sintaxis se utiliza para representar la extracción de cualquier tipo de objeto de la página.

Esto se puede usar al unísono para extraer identificadores y etiquetas de una página. Cada uno simplemente requiere los mismos símbolos utilizados en las declaraciones de CSS, como $ ('# myid') y $ ('. myclass'). Una vez dentro de la función lista, jQuery le permite extraer tantos eventos y funciones como necesite.
La biblioteca está optimizada para la velocidad y con el DOM actualmente avanza rápidamente, estamos viendo grandes avances en el soporte de scripting. Cada nodo se carga en una ranura de memoria de objetos que tanto el navegador web y desarrollador puede acceder.
Conclusión
El movimiento de código abierto también ha contribuido en gran medida al avance de las especificaciones de DOM. Durante los últimos 10 años, hemos visto que XML es bienvenido en la documentación junto con formas de definir fuentes de contenido (RSS, Atom, etc.).
Es importante estar al tanto de las tendencias como desarrollador web. La web está avanzando rápidamente y las últimas revisiones del Modelo de objeto de documento muestran cuánto control está disponible en la actualidad. Si desea profundizar en las secuencias de comandos DOM, le ofrecemos colecciones de trucos jQuery y muchos tutoriales de video de diseño web totalmente gratis.